kubeadm 升级k8s集群到v1.17.0
https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
本次实验我知道了一定要认证看官网文档,要认真仔细地看
Before you begin
- You need to have a kubeadm Kubernetes cluster running version 1.16.0 or later.
- Swap must be disabled.
- The cluster should use a static control plane and etcd pods or external etcd.
- Make sure you read the release notes carefully.
- Make sure to back up any important components, such as app-level state stored in a database.
kubeadm upgradedoes not touch your workloads, only components internal to Kubernetes, but backups are always a best practice.
Determine which version to upgrade to
通过下面命令可以查看到最新版本的软件包,可以看到,最新是1.17.0
[root@k8s-master1 ~]# apt-cache policy kubeadm | head -10
kubeadm:
Installed: 1.16.3-00
Candidate: 1.17.0-00
Version table:
1.17.0-00 500
500 https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
*** 1.16.3-00 500
500 https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
100 /var/lib/dpkg/status
1.16.2-00 500
[root@k8s-master1 ~]# apt-cache madison kubeadm | head -10
kubeadm | 1.17.0-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.16.3-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.16.2-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.16.1-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.16.0-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.15.6-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.15.5-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.15.4-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.15.3-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.15.2-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
Upgrading control plane nodes
1、每个节点都更新kubeadm,kubectl,kubelet,只更新kubeadm
官网说,只是control plane node更新kubeadm(On your first control plane node, upgrade kubeadm:)官网是对的,我全装了kubeadm upgrade plan报错了,此时不需要操作node节点
apt install kubeadm=1.17.0-00 -y
2、看kubeadm版本
[root@k8s-master1 ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"17", GitVersion:"v1.17.0", GitCommit:"70132b0f130acc0bed193d9ba59dd186f0e634cf", GitTreeState:"clean", BuildDate:"2019-12-07T21:17:50Z", GoVersion:"go1.13.4", Compiler:"gc", Platform:"linux/amd64"}
3、Drain the control plane node:
我现在两个master其实有一个VIP,VIP在master1上,master1应该就是control plane node
[root@k8s-master1 ~]# kubectl drain k8s-master1 --ignore-daemonsets
node/k8s-master1 cordoned
evicting pod "coredns-58cc8c89f4-hrl59"
evicting pod "coredns-58cc8c89f4-sztnn"
pod/coredns-58cc8c89f4-hrl59 evicted
pod/coredns-58cc8c89f4-sztnn evicted
node/k8s-master1 evicted
#node2也操作了算了
[root@k8s-master1 ~]# kubectl drain k8s-master2 --ignore-daemonsets
node/k8s-master2 cordoned
node/k8s-master2 drained
此时业务貌似是可以正常访问的
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady,SchedulingDisabled master 47h v1.17.0
k8s-master2 NotReady master 46h v1.17.0
k8s-node1 NotReady <none> 46h v1.17.0
4、On the control plane node, run:
VIP在master1上,应该就是master1,我因为kubeadm,kubectl,kubelet全更新而报错:https://xyz.uscwifi.xyz/post/kubeadm-upgrade-plan报错记/
[root@k8s-master1 ~]# kubeadm upgrade plan
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks.
[upgrade] Making sure the cluster is healthy:
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.16.3
[upgrade/versions] kubeadm version: v1.17.0
[upgrade/versions] Latest stable version: v1.17.0
[upgrade/versions] Latest version in the v1.16 series: v1.16.4
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT AVAILABLE
Kubelet 3 x v1.16.3 v1.16.4
Upgrade to the latest version in the v1.16 series:
COMPONENT CURRENT AVAILABLE
API Server v1.16.3 v1.16.4
Controller Manager v1.16.3 v1.16.4
Scheduler v1.16.3 v1.16.4
Kube Proxy v1.16.3 v1.16.4
CoreDNS 1.6.2 1.6.5
Etcd 3.3.15 3.3.17-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.16.4
_____________________________________________________________________
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT AVAILABLE
Kubelet 3 x v1.16.3 v1.17.0
Upgrade to the latest stable version:
COMPONENT CURRENT AVAILABLE
API Server v1.16.3 v1.17.0
Controller Manager v1.16.3 v1.17.0
Scheduler v1.16.3 v1.17.0
Kube Proxy v1.16.3 v1.17.0
CoreDNS 1.6.2 1.6.5
Etcd 3.3.15 3.4.3-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.17.0
_____________________________________________________________________
5、选择一个版本升级
[root@k8s-master1 ~]# kubeadm upgrade apply v1.17.0
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks.
[upgrade] Making sure the cluster is healthy:
[upgrade/version] You have chosen to change the cluster version to "v1.17.0"
[upgrade/versions] Cluster version: v1.16.3
[upgrade/versions] kubeadm version: v1.17.0
[upgrade/confirm] Are you sure you want to proceed with the upgrade? [y/N]: y
[upgrade/prepull] Will prepull images for components [kube-apiserver kube-controller-manager kube-scheduler etcd]
[upgrade/prepull] Prepulling image for component etcd.
[upgrade/prepull] Prepulling image for component kube-apiserver.
[upgrade/prepull] Prepulling image for component kube-controller-manager.
[upgrade/prepull] Prepulling image for component kube-scheduler.
[apiclient] Found 0 Pods for label selector k8s-app=upgrade-prepull-kube-apiserver
[apiclient] Found 0 Pods for label selector k8s-app=upgrade-prepull-etcd
[apiclient] Found 1 Pods for label selector k8s-app=upgrade-prepull-kube-controller-manager
[apiclient] Found 0 Pods for label selector k8s-app=upgrade-prepull-kube-scheduler
[apiclient] Found 2 Pods for label selector k8s-app=upgrade-prepull-kube-scheduler
[apiclient] Found 2 Pods for label selector k8s-app=upgrade-prepull-kube-controller-manager
[apiclient] Found 2 Pods for label selector k8s-app=upgrade-prepull-kube-apiserver
[apiclient] Found 2 Pods for label selector k8s-app=upgrade-prepull-etcd
[upgrade/prepull] Prepulled image for component kube-apiserver.
[upgrade/prepull] Prepulled image for component kube-controller-manager.
[upgrade/prepull] Prepulled image for component kube-scheduler.
[upgrade/prepull] Prepulled image for component etcd.
[upgrade/prepull] Successfully prepulled the images for all the control plane components
[upgrade/apply] Upgrading your Static Pod-hosted control plane to version "v1.17.0"...
Static pod: kube-apiserver-k8s-master1 hash: 9df6415ad3320e03ac807cfc4c7c76ff
Static pod: kube-controller-manager-k8s-master1 hash: 3084bcd4ec9338eb0884edfbf008e296
Static pod: kube-scheduler-k8s-master1 hash: f48641826bbe4a7f22cd206f2178ae9e
[upgrade/etcd] Upgrading to TLS for etcd
Static pod: etcd-k8s-master1 hash: ae224521aaf440e1c2578d91c74b4ed3
[upgrade/staticpods] Preparing for "etcd" upgrade
[upgrade/staticpods] Renewing etcd-server certificate
[upgrade/staticpods] Renewing etcd-peer certificate
[upgrade/staticpods] Renewing etcd-healthcheck-client certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/etcd.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2019-12-13-15-42-13/etcd.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: etcd-k8s-master1 hash: ae224521aaf440e1c2578d91c74b4ed3
Static pod: etcd-k8s-master1 hash: ae224521aaf440e1c2578d91c74b4ed3
Static pod: etcd-k8s-master1 hash: a95be3a42996921b3f85d7b21d414e9d
[apiclient] Found 2 Pods for label selector component=etcd
[upgrade/staticpods] Component "etcd" upgraded successfully!
[upgrade/etcd] Waiting for etcd to become available
[upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests177066084"
W1213 15:42:29.864142 116563 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[upgrade/staticpods] Preparing for "kube-apiserver" upgrade
[upgrade/staticpods] Renewing apiserver certificate
[upgrade/staticpods] Renewing apiserver-kubelet-client certificate
[upgrade/staticpods] Renewing front-proxy-client certificate
[upgrade/staticpods] Renewing apiserver-etcd-client certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-apiserver.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2019-12-13-15-42-13/kube-apiserver.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: kube-apiserver-k8s-master1 hash: 9df6415ad3320e03ac807cfc4c7c76ff
Static pod: kube-apiserver-k8s-master1 hash: 53c2f60d2133b2ce8a539c8ddc6f5aa6
[apiclient] Found 2 Pods for label selector component=kube-apiserver
[upgrade/staticpods] Component "kube-apiserver" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-controller-manager" upgrade
[upgrade/staticpods] Renewing controller-manager.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-controller-manager.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2019-12-13-15-42-13/kube-controller-manager.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: kube-controller-manager-k8s-master1 hash: 3084bcd4ec9338eb0884edfbf008e296
Static pod: kube-controller-manager-k8s-master1 hash: 65f88f0c94f6910111c83fd5bc9b34f3
[apiclient] Found 2 Pods for label selector component=kube-controller-manager
[upgrade/staticpods] Component "kube-controller-manager" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-scheduler" upgrade
[upgrade/staticpods] Renewing scheduler.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-scheduler.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2019-12-13-15-42-13/kube-scheduler.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: kube-scheduler-k8s-master1 hash: f48641826bbe4a7f22cd206f2178ae9e
Static pod: kube-scheduler-k8s-master1 hash: f4ee3eb1313e3a8694c8914ebcebacd7
[apiclient] Found 2 Pods for label selector component=kube-scheduler
[upgrade/staticpods] Component "kube-scheduler" upgraded successfully!
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.17" in namespace kube-system with the configuration for the kubelets in the cluster
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.17" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[addons]: Migrating CoreDNS Corefile
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.17.0". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.
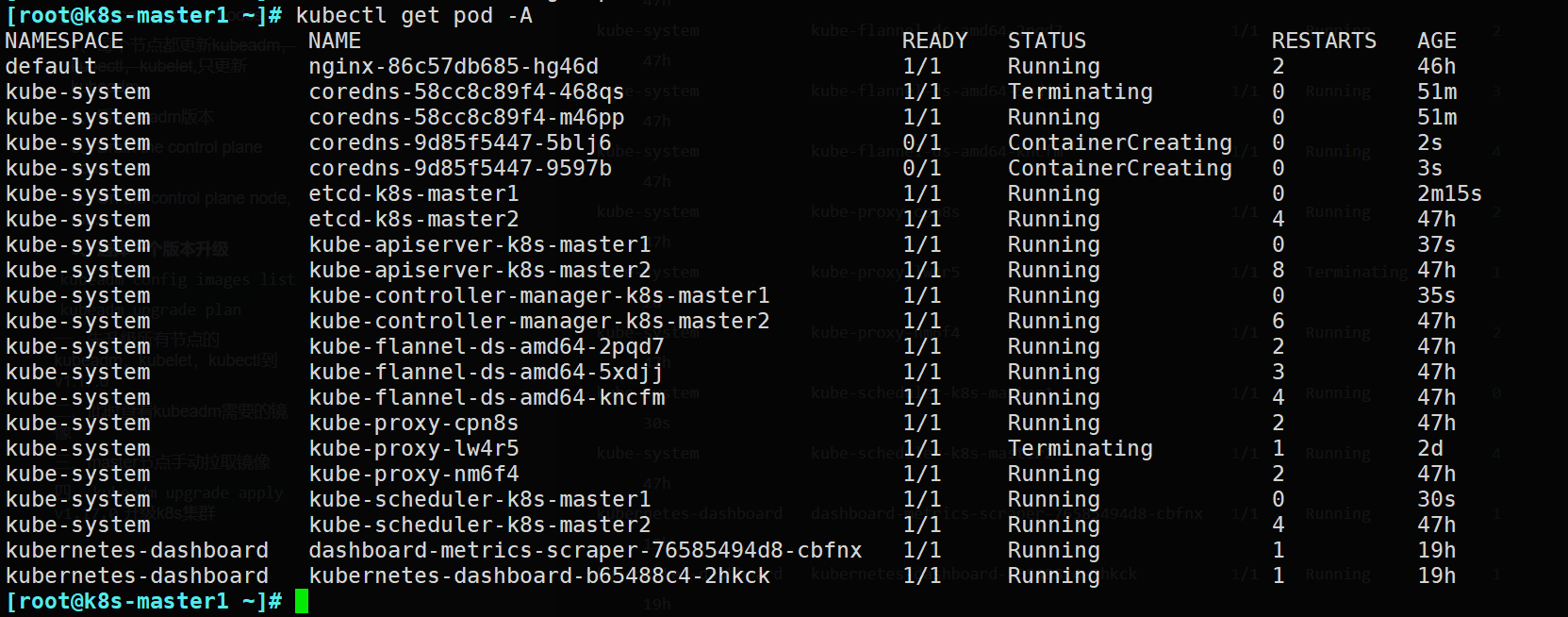
可以看到,有一部分pod更新了
[root@k8s-master1 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default nginx-86c57db685-hg46d 1/1 Running 2 46h
kube-system coredns-58cc8c89f4-468qs 1/1 Terminating 0 51m
kube-system coredns-58cc8c89f4-m46pp 1/1 Running 0 51m
kube-system coredns-9d85f5447-5blj6 0/1 ContainerCreating 0 2s
kube-system coredns-9d85f5447-9597b 0/1 ContainerCreating 0 3s
kube-system etcd-k8s-master1 1/1 Running 0 2m15s
kube-system etcd-k8s-master2 1/1 Running 4 47h
kube-system kube-apiserver-k8s-master1 1/1 Running 0 37s
kube-system kube-apiserver-k8s-master2 1/1 Running 8 47h
kube-system kube-controller-manager-k8s-master1 1/1 Running 0 35s
kube-system kube-controller-manager-k8s-master2 1/1 Running 6 47h
kube-system kube-flannel-ds-amd64-2pqd7 1/1 Running 2 47h
kube-system kube-flannel-ds-amd64-5xdjj 1/1 Running 3 47h
kube-system kube-flannel-ds-amd64-kncfm 1/1 Running 4 47h
kube-system kube-proxy-cpn8s 1/1 Running 2 47h
kube-system kube-proxy-lw4r5 1/1 Terminating 1 2d
kube-system kube-proxy-nm6f4 1/1 Running 2 47h
kube-system kube-scheduler-k8s-master1 1/1 Running 0 30s
kube-system kube-scheduler-k8s-master2 1/1 Running 4 47h
kubernetes-dashboard dashboard-metrics-scraper-76585494d8-cbfnx 1/1 Running 1 19h
kubernetes-dashboard kubernetes-dashboard-b65488c4-2hkck 1/1 Running 1 19h
6、手动更新网络插件
这一步我应该不用操作
7、Uncordon the control plane node
不知道对不对
[root@k8s-master1 ~]# kubectl uncordon k8s-master1
node/k8s-master1 uncordoned
[root@k8s-master1 ~]# kubectl uncordon k8s-master2
node/k8s-master2 uncordoned
Upgrade additional control plane nodes
1、Same as the first control plane node but use
[root@k8s-master1 ~]# kubeadm upgrade node
[upgrade] Reading configuration from the cluster...
[upgrade] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[upgrade] Upgrading your Static Pod-hosted control plane instance to version "v1.17.0"...
Static pod: kube-apiserver-k8s-master1 hash: 53c2f60d2133b2ce8a539c8ddc6f5aa6
Static pod: kube-controller-manager-k8s-master1 hash: 65f88f0c94f6910111c83fd5bc9b34f3
Static pod: kube-scheduler-k8s-master1 hash: f4ee3eb1313e3a8694c8914ebcebacd7
[upgrade/etcd] Upgrading to TLS for etcd
[upgrade/etcd] Non fatal issue encountered during upgrade: the desired etcd version for this Kubernetes version "v1.17.0" is "3.4.3-0", but the current etcd version is "3.4.3". Won't downgrade etcd, instead just continue
[upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests294380952"
W1213 15:48:54.510267 123276 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[upgrade/staticpods] Preparing for "kube-apiserver" upgrade
[upgrade/staticpods] Current and new manifests of kube-apiserver are equal, skipping upgrade
[upgrade/staticpods] Preparing for "kube-controller-manager" upgrade
[upgrade/staticpods] Current and new manifests of kube-controller-manager are equal, skipping upgrade
[upgrade/staticpods] Preparing for "kube-scheduler" upgrade
[upgrade/staticpods] Current and new manifests of kube-scheduler are equal, skipping upgrade
[upgrade] The control plane instance for this node was successfully updated!
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.17" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[upgrade] The configuration for this node was successfully updated!
[upgrade] Now you should go ahead and upgrade the kubelet package using your package manager.
Upgrade kubelet and kubectl
1、这一步才是安装kubelet和kubectl
在所有master节点操作
[root@k8s-master1 ~]# apt install kubelet=1.17.0-00 kubectl=1.17.0-00 -y
[root@k8s-master2 ~]# apt install kubelet=1.17.0-00 kubectl=1.17.0-00 -y
2、重启kubelet
[root@k8s-master1 ~]# systemctl restart kubelet
[root@k8s-master2 ~]# systemctl restart kubelet
Upgrade worker nodes
1、所有worker节点更新kubeadm
[root@k8s-node1 ~]# apt install kubeadm=1.17.0-00 -y
2、node节点进入维护模式
让node节点变成不可调度状态
[root@k8s-master1 ~]# kubectl drain k8s-node1 --ignore-daemonsets
node/k8s-node1 cordoned
evicting pod "nginx-86c57db685-hg46d"
evicting pod "coredns-9d85f5447-5blj6"
evicting pod "coredns-9d85f5447-9597b"
pod/coredns-9d85f5447-9597b evicted
pod/nginx-86c57db685-hg46d evicted
pod/coredns-9d85f5447-5blj6 evicted
node/k8s-node1 evicted
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready master 2d v1.17.0
k8s-master2 Ready master 47h v1.17.0
k8s-node1 Ready,SchedulingDisabled <none> 47h v1.16.3
3、更新kubelet configuration
[root@k8s-master1 ~]# kubeadm upgrade node
[upgrade] Reading configuration from the cluster...
[upgrade] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[upgrade] Upgrading your Static Pod-hosted control plane instance to version "v1.17.0"...
Static pod: kube-apiserver-k8s-master1 hash: 53c2f60d2133b2ce8a539c8ddc6f5aa6
Static pod: kube-controller-manager-k8s-master1 hash: 65f88f0c94f6910111c83fd5bc9b34f3
Static pod: kube-scheduler-k8s-master1 hash: f4ee3eb1313e3a8694c8914ebcebacd7
[upgrade/etcd] Upgrading to TLS for etcd
[upgrade/etcd] Non fatal issue encountered during upgrade: the desired etcd version for this Kubernetes version "v1.17.0" is "3.4.3-0", but the current etcd version is "3.4.3". Won't downgrade etcd, instead just continue
[upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests049519615"
W1213 16:01:05.697712 129810 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[upgrade/staticpods] Preparing for "kube-apiserver" upgrade
[upgrade/staticpods] Current and new manifests of kube-apiserver are equal, skipping upgrade
[upgrade/staticpods] Preparing for "kube-controller-manager" upgrade
[upgrade/staticpods] Current and new manifests of kube-controller-manager are equal, skipping upgrade
[upgrade/staticpods] Preparing for "kube-scheduler" upgrade
[upgrade/staticpods] Current and new manifests of kube-scheduler are equal, skipping upgrade
[upgrade] The control plane instance for this node was successfully updated!
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.17" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[upgrade] The configuration for this node was successfully updated!
[upgrade] Now you should go ahead and upgrade the kubelet package using your package manager.
4、更新worker节点的kubelet和kubectl
所有worker节点都要操作
[root@k8s-node1 ~]# apt install kubelet=1.17.0-00 kubectl=1.17.0-00 -y
5、重启worker节点的kubelet
[root@k8s-node1 ~]# systemctl restart kubelet
6、Uncordon the node
Bring the node back online by marking it schedulable:让所有worker节点变成可以被调度的状态
[root@k8s-master1 ~]# kubectl uncordon k8s-node1
node/k8s-node1 uncordoned
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready master 2d v1.17.0
k8s-master2 Ready master 47h v1.17.0
k8s-node1 Ready <none> 47h v1.17.0
Verify the status of the cluster
都ready了
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready master 2d v1.17.0
k8s-master2 Ready master 47h v1.17.0
k8s-node1 Ready <none> 47h v1.17.0
华丽的分割线,下面内容不要,上面操作步骤完全可用
kubeadm config images list
**该命令可以列出kubeadm将会用到的一些镜像。**下面提示有个更新的版本1.17.0
[root@k8s-master1 ~]# kubeadm config images list --image-repository registry.aliyuncs.com/google_containers
I1213 13:25:25.043887 16565 version.go:251] remote version is much newer: v1.17.0; falling back to: stable-1.16
registry.aliyuncs.com/google_containers/kube-apiserver:v1.16.4
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.16.4
registry.aliyuncs.com/google_containers/kube-scheduler:v1.16.4
registry.aliyuncs.com/google_containers/kube-proxy:v1.16.4
registry.aliyuncs.com/google_containers/pause:3.1
registry.aliyuncs.com/google_containers/etcd:3.3.15-0
registry.aliyuncs.com/google_containers/coredns:1.6.2
kubeadm upgrade plan
检查可用于升级到哪些版本,并验证当前集群是否可以升级,默认需要科学上网
同时下面提示可以通过kubectl -n kube-system get cm kubeadm-config -oyaml查看配置文件
[root@k8s-master1 ~]# kubeadm upgrade plan
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks.
[upgrade] Making sure the cluster is healthy:
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.16.3
[upgrade/versions] kubeadm version: v1.16.3
I1213 13:32:23.052637 19885 version.go:251] remote version is much newer: v1.17.0; falling back to: stable-1.16
[upgrade/versions] Latest stable version: v1.16.4
[upgrade/versions] Latest version in the v1.16 series: v1.16.4
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT AVAILABLE
Kubelet 3 x v1.16.3 v1.16.4
Upgrade to the latest version in the v1.16 series:
COMPONENT CURRENT AVAILABLE
API Server v1.16.3 v1.16.4
Controller Manager v1.16.3 v1.16.4
Scheduler v1.16.3 v1.16.4
Kube Proxy v1.16.3 v1.16.4
CoreDNS 1.6.2 1.6.2
Etcd 3.3.15 3.3.15-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.16.4
Note: Before you can perform this upgrade, you have to update kubeadm to v1.16.4.
_____________________________________________________________________
也可以直接后面根指定版本看能否升级,比如1.17.0,这个下面就是个模版输出,并不检查v1.17.0是否存在,并告诉你要先升级kubeadm,kubelet再kubeadm apply
[root@k8s-master1 ~]# kubeadm upgrade plan v1.17.0
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks.
[upgrade] Making sure the cluster is healthy:
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.16.3
[upgrade/versions] kubeadm version: v1.16.3
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT AVAILABLE
Kubelet 3 x v1.16.3 v1.17.0
Upgrade to the latest version in the v1.16 series:
COMPONENT CURRENT AVAILABLE
API Server v1.16.3 v1.17.0
Controller Manager v1.16.3 v1.17.0
Scheduler v1.16.3 v1.17.0
Kube Proxy v1.16.3 v1.17.0
CoreDNS 1.6.2 1.6.2
Etcd 3.3.15 3.3.15-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.17.0
Note: Before you can perform this upgrade, you have to update kubeadm to v1.17.0.
_____________________________________________________________________
一、先升级所有节点的kubeadm,kubelet,kubectl到v1.17.0
所有节点都要操作
apt install kubeadm=1.17.0-00 kubelet=1.17.0-00 kubectl=1.17.0-00 -y
二、此时查看kubeadm需要的镜像
[root@k8s-master1 ~]# kubeadm config images list --image-repository registry.aliyuncs.com/google_containers
W1213 13:52:57.836382 31962 validation.go:28] Cannot validate kube-proxy config - no validator is available
W1213 13:52:57.836446 31962 validation.go:28] Cannot validate kubelet config - no validator is available
registry.aliyuncs.com/google_containers/kube-apiserver:v1.17.0
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.17.0
registry.aliyuncs.com/google_containers/kube-scheduler:v1.17.0
registry.aliyuncs.com/google_containers/kube-proxy:v1.17.0
registry.aliyuncs.com/google_containers/pause:3.1
registry.aliyuncs.com/google_containers/etcd:3.4.3-0
registry.aliyuncs.com/google_containers/coredns:1.6.5
三、master节点手动拉取镜像
两个master节点都要操作
[root@k8s-master1 ~]# kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers
W1213 13:56:16.856737 34965 validation.go:28] Cannot validate kube-proxy config - no validator is available
W1213 13:56:16.856840 34965 validation.go:28] Cannot validate kubelet config - no validator is available
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.17.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.17.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.17.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.17.0
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.1
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.4.3-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:1.6.5
四、kubeadm upgrade apply v1.17.0升级k8s集群
很遗憾报错了
[root@k8s-master1 ~]# kubeadm upgrade apply v1.17.0
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks.
[upgrade] Making sure the cluster is healthy:
[upgrade/health] FATAL: [preflight] Some fatal errors occurred:
[ERROR ControlPlaneNodesReady]: there are NotReady control-planes in the cluster: [k8s-master1 k8s-master2]
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
不用慌,毕竟我没按官方教程来,该页面当前给出的是1.16.x升级1.17.x,每个版本升级似乎都有不同:
https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
kubectl drain --help这个命令应该是用来将master节点置为维护状态,不再接收新请求用的
[root@k8s-master1 ~]# kubectl drain --help
Drain node in preparation for maintenance.
The given node will be marked unschedulable to prevent new pods from arriving. 'drain' evicts the pods if the APIServer
supportshttp://kubernetes.io/docs/admin/disruptions/ . Otherwise, it will use normal DELETE to delete the pods. The
'drain' evicts or deletes all pods except mirror pods (which cannot be deleted through the API server). If there are
DaemonSet-managed pods, drain will not proceed without --ignore-daemonsets, and regardless it will not delete any
DaemonSet-managed pods, because those pods would be immediately replaced by the DaemonSet controller, which ignores
unschedulable markings. If there are any pods that are neither mirror pods nor managed by ReplicationController,
ReplicaSet, DaemonSet, StatefulSet or Job, then drain will not delete any pods unless you use --force. --force will
also allow deletion to proceed if the managing resource of one or more pods is missing.
'drain' waits for graceful termination. You should not operate on the machine until the command completes.
When you are ready to put the node back into service, use kubectl uncordon, which will make the node schedulable again.
http://kubernetes.io/images/docs/kubectl_drain.svg
Examples:
# Drain node "foo", even if there are pods not managed by a ReplicationController, ReplicaSet, Job, DaemonSet or
StatefulSet on it.
$ kubectl drain foo --force
# As above, but abort if there are pods not managed by a ReplicationController, ReplicaSet, Job, DaemonSet or
StatefulSet, and use a grace period of 15 minutes.
$ kubectl drain foo --grace-period=900
Options:
--delete-local-data=false: Continue even if there are pods using emptyDir (local data that will be deleted when
the node is drained).
--dry-run=false: If true, only print the object that would be sent, without sending it.
--force=false: Continue even if there are pods not managed by a ReplicationController, ReplicaSet, Job, DaemonSet
or StatefulSet.
--grace-period=-1: Period of time in seconds given to each pod to terminate gracefully. If negative, the default
value specified in the pod will be used.
--ignore-daemonsets=false: Ignore DaemonSet-managed pods.
--pod-selector='': Label selector to filter pods on the node
-l, --selector='': Selector (label query) to filter on
--timeout=0s: The length of time to wait before giving up, zero means infinite
Usage:
kubectl drain NODE [options]
Use "kubectl options" for a list of global command-line options (applies to all commands).